So, in a previous post, I talked about the problem with translating differential equations into computer simulations. I did a lot of talking, but I didn't really say much that was useful. Here are four different methods of integrating the newtonian equations of motion, that are used frequently in simulation.
Explicit Euler
Explicit Euler integration, according to Physics for Flash Games, Animation, and Simulations an explicit, first order accurate, and very fast integration scheme. Acceleration is calculated each frame in a simulation, but for our purposes, we can treat it as constant, and deal with a simple falling body, therefore
Velocity can be simply integrated as:
We if we split up each t into time steps, we then have:
Going back to my textbook, that means that our position can be given as:
This is Euler integration, and it is used by most programmers who don't need enormous accuracy or stability. And it's a good thing they don't, because if they did, they might need to try something new something like...
Position Verlet
Position Verlet, usually just verlet, is a way of using not the first, but the second derivative of the acceleration equation to determine the motion of the particle. If we have our acceleration, and current position, we don't even need to look at the velocity, we have all the information we need to move the particle through the equations of motion. WRONG, we don't have all we need, inertia depends on velocity, and for velocity, we need to know where it was before. So, in verlet integration if:
then, we skip the velocity:
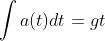 and work with the second derivative:
and work with the second derivative:
Discretizing this turns out to be tricky, but my book has the answer, and, if you care, an implementation of Verlet Integration can be found here (https://sites.google.com/site/stylustechnology/recent-stuff/balls), where it is used to simulate a large pile of balls. Again, my book gives the result:
Our final scheme is one that I have not yet implemented, but I get the idea.
Second Order Runge-Kutta Integration
This is a way of taking a framework that looks a lot like euler integration, and making it more accurate. It takes the values of position and velocity at the beginning and end of a frame, and averages them. This is like taking the time step and halving it doubling the accuracy. It is also known as Improved Euler integration, and you will see that the final position and velocity equations are actually the Explicit Euler equations in disguise.
First, define the values of position, velocity, and acceleration, at the beginning of the time step:
Then, recalculate all values at the end of the time step:
Finally, use that to calculate velocity, then position:
And there you have it, three numerical integration schemes, I hope I have managed to make this a little easier of a topic. There is also a fourth-order Runge-Kutta which is similar to the one that I have outlined, but that is a lot longer, and I don't feel like writing out all of the equations. Take a look for your self: http://en.wikipedia.org/wiki/Runge%E2%80%93Kutta_methods#Common_fourth-order_Runge.E2.80.93Kutta_method. Or alternatively, write up an animation of your own, using one of these schemes, and when you have, comment with the link, and make sure to include your source code!




